DNA & RNA: The foundation of life on Earth
All living things on Earth encode all of their essential building blocks – mostly proteins – in long chains of repeating molecules called DNA, deoxyribose nucleic acid. The sum total of all of the DNA that an organism has constitutes its genome. Viruses, possibly remnants of the earliest self-replicating things on Earth, can also encode their genomes in RNA (ribonucleic acid) strands, but viruses are not alive in the same sense that a cell or an animal is.
In this section, we'll look at the structures of DNA and RNA at various levels of detail, and learn how these molecules encode, or store the "blueprints" for proteins and other molecules needed by living things.

Nucleic acid polymers

Nucleic acid polymers come in two forms, RNA and DNA. Both are long chains of three-part moeties called nucleotide-phosphates. Don't worry too much about the names or the exact chemical structures for now. In fact, you can know a lot about biology without knowing those things.
The figure shows two nucleotide polymers paired up and pointing in opposite directions. So already we know that nucleotide polymers have a start and an end – a front and a back. More on that later.
Each of the chains is composed of a backbone made of alternating phosphate (PO4) molecules (P) and a 5-carbon sugar molecule (the pentagons labeled S). In RNA that sugar is ribose and in DNA it is deoxyribose. As the name suggests, deoxyribose has one fewer oxygen atom than ribose, and that's it. The consequences of this slight change are profound, as we shall see.
Each of the sugar molecules of these backbone chains serves as a bridge to bind one of four nucleotide bases: adenine (A), thymine (T), guanine (G) and cytosine (C) to the chain. You can think of the phosphate-sugar backbone as just a scaffold system for displaying the bases. In RNA, thymine is replaced by a similar molecule, uracil (U), the only other major structural difference between RNA and DNA.
DNA molecules exist almost exclusively as base-pared dimers in which two DNA strands are complementary: A G on one strand binds weakly to a C on the other, and a T on one strand binds weakly to an A on the other. These complementary DNA strands then coil into the well-known DNA double helix structure shown at the top of the page.
RNA, on the other hand, can exist as a single or double-stranded structure, and often has features of both, yielding a variety of 3-dimensional structures.
Next we'll discuss each of the building blocks of nucleic acid polymers, starting with the bases themselves, then see how they're all put together.
Bases: the pyrimidines
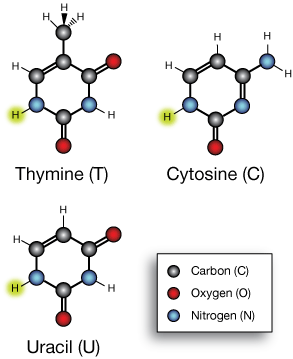
The core components of DNA and RNA are the nucleotide bases. These come in two categories, the pyrimidines and the purines. The pyrimidines are six-membered carbon-nitrogen rings with various side groups that include thymine (abbreviated T), cytosine (C) and uracil (U).
In a sense, DNA and RNA molecules are extended chains of linked bases. They are linked to a backbone of alternating phosphate and sugar molecules, as we shall see.
The base cytosine is found in both DNA and RNA, but while DNA incorporates the base thymine, RNA uses the base uracil in its place. The two differ by the methyl (CH3) group, which is a hydrogen in uracil.
The yellow hydrogens (H) are where we will link the sugar ribose (or deoxyribose) later.
Bases: the purines
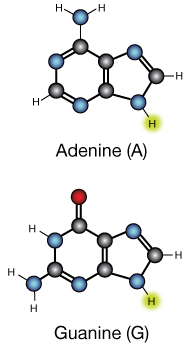
The two purine bases, composed of linked six- and five membered carbon-nitrogen rings, are found in both DNA and RNA.
The yellow H-atoms are removed for binding to the sugar ribose (in RNA) or its derivative deoxyribose (in DNA).
The nitrogen atoms in both purines and pyrimidines are crucial for hydrogen bonding (H-bonding) between bases, and that H-bonding is critical for formation of the DNA double helix.
All nucleotide bases are planar (flat) molecules. That geometry has an important consequence for the structure of long DNA and RNA chains.
About molecular drawings
The molecular models drawn above are "ball & stick" models. More frequently, you will see the DNA bases represented in the shorthand form below, in which most carbons are implied. In these diagrams, every unlabeled vertex, like the one just below the H at the "top" of cytosine, is a carbon atom. Double lines represent double
bonds; single lines are single bonds. Almost always, carbon atoms must form four bonds.
The bases on the top row are pyrimidines (one ring) and those on the bottom are purines (two rings). The ring structures here are referred to as heterocyclic compounds because the ring is composed of both carbon and nitrogen
The five nucleotide bases used by living things on Earth

The sugars: ribose
Ribose is a five-carbon sugar that is a crucial part of any DNA or RNA chain. It's what links each base to the phosphate backbone that links up the chain.
Ribose is what distinguishes RNA (ribo-nucleic acid) from DNA. DNA contains ribose sugars from which one of the hydroxyl (OH) groups has been removed to form deoxyribose. DNA is deoxyribo-nucleic acid.
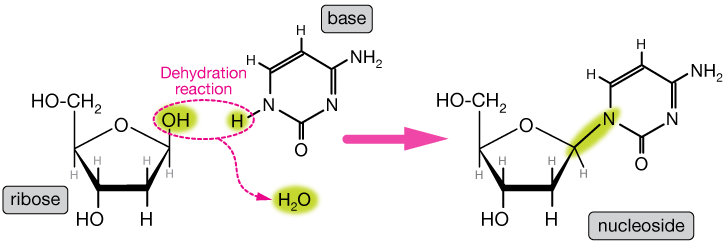
The yellow OH group detaches to form the bond to a base to form a nucleoside, and the yellow H is the site of bonding of the sugar to the phosphate backbone.

Labeling the carbon atoms of ribose
The carbon atoms (red dots here) of ribose and deoxyribose, like those of all sugars, are labeled with a particular scheme. We label the carbons clockwise from the one just after the in-ring oxygen atom (called the heteroatom) using 1', 2', ... 5', where we pronounce 5' as "five prime," and so on.
Binding of the backbone occurs at the 5' and 3' positions, and the base is located at the 1' position. DNA and RNA are read or transcribed in the 5' to 3' direction, always.

Formation of a nucleoside
A nucleoside is formed when a ribose or deoxyribose are linked in a dehydration reaction (a reaction that liberates a water molecule in the process of forming a new bond). Here is a very simplified version of the reaction that forms deoxyribo-cytosine, or cytosine nucleoside. The actual reaction requires a few enzymes. The base is always attached to the 1' carbon atom of the sugar.
Nucleoside phosphates
Now to complete the building blocks of DNA and RNA we need to add the phosphate (PO43-) group. To build a DNA or RNA polymer or strand, nucleosides are linked through the phosphate group. Two examples of nucleoside phosphates are shown below.
On the left is the DNA building block deoxyribose adenine phosphate and on the right is the RNA subunit ribose uracil phosphate. By changing the base we can derive each of the three other nucleoside phosphates. The hilighted oxygen atom is the site of bonding to the next nucleoside in the chain.

Putting it all together: the phosphate backbone

Now let's put those nucleotides together to make a chain. I'll stick with DNA for now and we'll get back to RNA later.
All that's required to link nucleotides is to form the continuous backbone of the chain by forming a series of —C—O—P—O—C— ... bonds, called phosphodiester bonds between the ribose sugars of the nucleosides.
These bonds are formed in a series of enzyme-catalyzed reactions that actually degrade the di-phosphate and tri-phosphate form of each nucleotide (below) to derive the monophophate form and recover the energy from those broken bonds to drive the reaction.

Chains of nucleotides of RNA and DNA can be between 10 and several million nucleotides!
Remember in staring at such a diagram, that every unlabeled vertex between bonds is a carbon atom.
The unique geometry of the deoxyribose sugar forces a twist in long chains of DNA, leading to the helical structure we see in a complete DNA strand consisting of two of these chains coupled together. More on that below.
DNA and RNA strands have a direction

According to the labeling convention for the carbons of sugars (see above), the phosphates bind to the ribose/deoxyribose sugars at the 3' and 5' positions, and the base is attached at the 1' position. So a DNA or RNA strand has a direction. We generally read and write the sequence of bases in the 5' to 3' ("5-prime to 3-prime") direction. Most of the biochemical processes that happen to DNA and RNA, like replication or reading of the sequence information for transcription, happen in this direction, too.
DNA and RNA strands are polymers composed of the purine or pyrimidine bases A, C, G and T (or U in RNA), bound to the 1' carbon of the 5-carbon sugar ribose. The sugar-base pair is called a nucleoside. Each nucleoside is bound to another by a phosphate through phosphodiester bonds connecting the 5' carbon of one ribose to the 3' carbon of the next.
Base pairing in DNA
In almost all situations, DNA strands occur in complementary pairs that stick to each other through specific base-to-base hydrogen bonds. It turns out that the bases nature has selected for use in DNA fit perfectly to one another in specific pairings: One purine and one pyrimidine, A to T and G to C.
The figure below shows the pairings. The lone pairs of oxygen and nitrogen atoms act as H-bond acceptors for the protons of amine groups of the bases. Adenine and thymine share a pair of H-bonds and Guanine-cytosine pairs share three bonds. These are the only base-pairs that ever occur in DNA: A-T and G-C.


Complementary strands
DNA is a very complicated molecule and often we're just interested in the sequence of bases in its strands. A common representation of the sequence of both complementary strands looks like this:

Notice that every T is paired with an A and every G is paired with a C.
3-D representations of DNA
There are many ways to represent the 3-dimensional structure of DNA. Short lengths of DNA are shown below in a variety of forms. On the left is a ($4000 !) ball & stick model that decorates Sheldon and Leonard's apartment in the CBS TV series The Big Bang Theory. The black-and-white space-filling drawing may be the most accurate representation because it more faithfully represents the space taken up by the electron clouds of the atoms.
In that representation it's easy to see that the DNA double helix possesses two grooves; the smaller is the minor groove and the larger is the major grooove. The stick model with the black background is typical of a computer 3-D model used to examine structure closely. Notice in all models that the base pairs are coplanar. The simple representation on the right distills all of the detail down to its essence: two twisted strands attached by complementary bases.

Why the twist?

Double-stranded DNA takes on the form of a double helix (a 3-dimensional spiral, or rather two intertwined 3D spirals). If we look at it in the 5' to 3' direction, it's a right-handed helix. The right hand rule works like the sketch on the right: Point your thumb along the 5'-3' direction and the curvature moves upward in the direction that your fingers curl around.
DNA takes on this form for a variety of reasons, all of which have to do with intermolecular forces. The phosphate/ribose backbone of DNA is hydrophillic (water loving), so it orients itself outward toward the solvent, while the relatively hydrophobic bases bury themselves inside. Additionally, the geometry of the deoxyribose-phosphate linkage allows for just the right pitch, or distance between strands in the helix, a pitch that nicely accommodates base pairing. Lots of things come together to create the beautiful right-handed double-helix structure.
RNA structure
Because of the structural differences between RNA and DNA (mainly due to the ribose-deoxyribose difference), the two molecules can adopt very different 3D structures. While DNA strands tend to coil into double helices*, RNA strands can either pair with a complementary strand or pair in certain regions with themselves. A good example is the transfer RNA, used by all living things on Earth to construct proteins from messenger RNA (mRNA) strands, shown here.
The diagram on the left schematically shows that the tRNA is a single strand, but that in four extended regions, it is complementary to itself (forms U-A and G-C pairs). This creates the 3-D structure shown, one that is crucial for the function accomplished by this molecule in cells.
Structure of a transfer RNA (tRNA)

Source: Front. Microbiol., 21 October 2020 | https://doi.org/10.3389/fmicb.2020.596914
polymer
In its Greek origins, poly means many and meros means shares or things — "many things". In chemistry, a polymer is a long chain of linked molecules of the same or similar type. Polyethylene is a polymer of ethylene molecules, often thousands of units long. Proteins and DNA are biological polymers of amino acids and nucleic acids, respectively.
Helix
A helix is a three-dimensional spiral. An extended spring is a helix. Helices (plural form) are different from spirals, which are two-dimensional curves. A helix is a three-dimensional object. The DNA double helix is two helices coiled together. Helices may be right or left handed, depending on the direction of twist from bottom to top.

![]()
xaktly.com by Dr. Jeff Cruzan is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License. © 2016-2025, Jeff Cruzan. All text and images on this website not specifically attributed to another source were created by me and I reserve all rights as to their use. Any opinions expressed on this website are entirely mine, and do not necessarily reflect the views of any of my employers. Please feel free to send any questions or comments to jeff.cruzan@verizon.net.