Some functions cannot be integrated analytically (on paper).
$$\int e^{\frac{1}{x}} \, dx$$
$$\int cos(x) \, ln(x) \, dx$$
$$\int sin(x^2) \, dx$$
$$\int \frac{cos(x)}{x} \, dx$$
The integrals above cannot be solved analytically, that is, with pencil and paper or by hand. They can't be expressed exactly as some combination of elementary functions.
Another way to say it is that for each of those integrals above (and many others), there is no combination of trigonometric, polynomial, root, exponential or logarithmic functions that can be found which, when differentiated, give back the integrand.
Those examples are just a few among a large number of integrals we can't solve exactly, so it's worth figuring out another way to do it.
In order to calculate those integrals (and we're always talking about definite integrals here), we need to employ numerical methods, which are always just approximations. The good news is that we can usually find all of the precision we need in our answer, as long as we're willing to spend enough time on it (and often that's computer processor time, so it's pretty fast).
In this section we'll discuss a few methods of numerical integration: Riemann integration, trapezoidal integration and Monte Carlo integration, and we'll talk about some limitations and work through some examples.
analytically
In this context, analytically means "on paper with a pencil or pen." That is, we can solve the problem exactly without a computer.
Not all functions can be integrated by hand
Every combination of elementary functions (like polynomials, exponential functions, trig. functions) has an analytical derivative (one that can be worked out on paper exactly), but not every integrand has an analytical antiderivative. Some antiderivatives can't be expressed in terms of elementary functions.
1. Riemann integration
You've seen Riemann integration as you developed the concept of the definite integral. It's a conceptually-easy method of finding the area under a curve when we run out of other options.
The scheme of Riemann integration is shown on the right. The yellow boxes are the left Riemann sum, so named because the height of each box is determined by where its top left corner intersects the function. By the same logic, the green boxes (behind) represent the right Riemann sum.
The area under the curve is broken into $n$ regions ($n=4$ here) of equal width, $\Delta x = (b-a)/n$, where $a$ and $b$ are the limits of the integral. Here are the summation expressions for $L_N$ and $R_N$, the left and right Riemann sums.

$$L_N = \Delta x \, \sum_{i = 0}^{N - 1} \, f(x + i \Delta x)$$
$$R_N = \Delta x \, \sum_{i = 1}^N \, f(x + i \Delta x)$$
In these sums $\Delta x$ is the width of each box and $N$ is the number of boxes.
We could imagine a number of scenarios for going after the value of an indefinite integral using Riemann sums.
We could perform a right or left sum only. Notice that in the diagram above the left sum underestimates a rising function and overestimates a falling function. It's the opposite for the right Riemann sum.
We might decide to calculate both right and left Riemann sums for some value of $N$, then average the two. That's really the same as taking a middle Riemann sum (the middle of each box is what intersects the function graph). The equation for that is:
$$M_N = \Delta x \, \sum_{i = 1}^N \, f(x + \left(i - \frac{1}{2} \right) \Delta x)$$
And in any case, we can increase the number of boxes until we get the level of precision we need —but there are limitations.
A left Riemann sum underestimates an increasing function and overestimates a decreasing function.
A right Riemann sum overestimates an increasing function and underestimates a decreasing function.
Example — Riemann integration
Let's use Riemann integration on a definite integral we know how to calculate:
$$f(x) = -(x - 2)^2 + 4$$
That function crosses the x-axis at $x=0$ and $x=4$, so if we find the area under the curve, we get
$$-\int_0^4 \, [(x - 2)^2 + 4] \, dx = \frac{32}{3}$$
32/3 is about 10.67. Below are three attempts to calculate this integral using left Riemann sums with 4, 8 and 16 divisions, respectively. The sums are within 7%, 2% and 0.3% of that exact value, respectively, not too bad.

| box | x | f(x) | $A_i$ | |
|---|---|---|---|---|
| 1 | 0 | 0 | 0 | |
| 2 | 1 | 3 | 3 | |
| 3 | 2 | 4 | 4 | |
| 4 | 3 | 3 | 3 | |
| Area = 10 | ||||

| box | x | f(x) | $A_i$ | |
|---|---|---|---|---|
| 1 | 0.0 | 0.00 | 0.00 | |
| 2 | 0.5 | 1.75 | 0.88 | |
| 3 | 1.0 | 3.00 | 1.50 | |
| 4 | 1.5 | 3.75 | 1.88 | |
| 5 | 2.0 | 4.00 | 2.00 | |
| 6 | 2.5 | 3.75 | 1.88 | |
| 7 | 3.0 | 3.00 | 1.50 | |
| 8 | 3.5 | 1.75 | 0.88 | |
| Area = 10.5 | ||||

| box | x | f(x) | $A_i$ | box | x | f(x) | $A_i$ | |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.00 | 0.00 | 0.00 | 9 | 2.00 | 4.00 | 1.00 | |
| 2 | 0.25 | 0.94 | 0.23 | 10 | 2.25 | 3.94 | 0.98 | |
| 3 | 0.50 | 1.75 | 0.44 | 11 | 2.50 | 3.75 | 0.94 | |
| 4 | 0.75 | 2.44 | 0.61 | 12 | 2.75 | 3.44 | 0.86 | |
| 5 | 1.00 | 3.00 | 0.75 | 13 | 3.00 | 3.00 | 0.75 | |
| 6 | 1.25 | 3.44 | 0.86 | 14 | 3.25 | 2.44 | 0.61 | |
| 7 | 1.50 | 3.75 | 0.94 | 15 | 3.50 | 1.75 | 0.44 | |
| 8 | 1.75 | 3.94 | 0.98 | 16 | 3.75 | 0.94 | 0.23 | |
| Area = 10.63 | ||||||||
Even with just 16 rectangles, the area is pretty close to the exact value. This won't be true for all functions, but then if you can automate Riemann integration, 1000 rectangles isn't difficult to acheive.
Implementation – some Python code
Here is a short bit of Python code that performs a left Riemann sum on a function that you can define in the function func(). Paste it into your favorite IDE (integrated developing environment) or just run it from the command line. Play with the number of rectangles to see convergence toward a more precise value of the integral. This particular block of code is set up to find the area under the cosine function, but you could change it to any other function.

2. Trapezoidal integration
For reasons that are obvious when you compare the figure on the right with Riemann integration, we would expect that fitting trapezoids under a curve would provide a better estimate of the area beneath it than rectangles. And like Riemann sums, the more trapezoids the better (but the gain in accuracy of both methods diminishes as the number of rectangles or trapezoids grows).
To refresh your memory, the area of a trapezoid is the width times the average of the lengths of the two parallel sides. The lengths of those sides can be calculated using the function: $f(x_o), \; f(x_1)$ for the left-most trapezoid, and so on. The area of the left-most trapezoid, where $(b-a)/n$ is the constant width of each, is
$$\int_a^b f(x) \, dx \approx \frac{b - a}{n} \sum_{i = 0}^{n - 1} \, [f(x_i) + f(x_{i + 1})]$$

If we add up the areas of all $n$ trapezoids, we get
$$= \frac{b - a}{2n}[f(x_0) + 2f(x_1) + \dots + 2 f(x_n) + f(x_{n+1})]$$
Notice that apart from $f(x_o)$ and $f(x_n)$ every other term appears twice, so we can simplify a bit:
$$\int_a^b f(x) \, dx \approx \frac{b - a}{n} \left[ \frac{f(x_0) + f(x_1)}{2} + \frac{f(x_1) + f(x_2)}{2} + \dots + \frac{f(x_{n - 1}) + f(x_n)}{2} \right]$$
Then in summation form, we define trapezoidal integration of a function divided into $n$ equal-width trapezoids with the trapezoid rule:
$$= \frac{b - a}{n} \left[ \frac{f(x_0) + f(x_n)}{2} \right] + f(x_1) + f(x_2) + \dots + f(x_{n - 1})$$
Example – Trapezoidal integration
Let's apply trapezoidal integration to the example function we integrated above, just to compare the two methods.
$$f(x) = -(x-2)^2+4$$
Let's do it for four and eight trapezoids. With any luck each should provide a better estimate of the area (32/3) than the Riemann sum with the same n. These are pretty easy to calculate. The case for n=4 is shown below, and yields the area is 10.0 units2 with just a simple approximation.

| trap. | $f(x_i)$ | $f(x_{i+1})$ | $A_i$ | |
|---|---|---|---|---|
| 1 | 0.00 | 3.00 | 1.50 | |
| 2 | 3.00 | 4.00 | 3.50 | |
| 3 | 4.00 | 3.00 | 3.50 | |
| 4 | 3.00 | 0.00 | 1.50 | |
| Area = 10.00 | ||||

| trap. | $f(x_i)$ | $f(x_{i+1})$ | $A_i$ | |
|---|---|---|---|---|
| 1 | 0.00 | 1.75 | 0.44 | |
| 2 | 1.75 | 3.00 | 1.19 | |
| 3 | 3.00 | 3.75 | 1.69 | |
| 4 | 3.75 | 4.00 | 1.94 | |
| 5 | 4.00 | 3.75 | 1.94 | |
| 6 | 3.75 | 3.00 | 1.69 | |
| 7 | 3.00 | 1.75 | 1.19 | |
| 8 | 1.75 | 0.00 | 0.96 | |
| Area = 10.50 | ||||
The solution using sixteen trapezoids is 10.63 square units, identical to our Riemann sum with 16 divisions. This brings up a couple of interesting points.
First, The integrand in this example is a symmetric function, so the right and left Riemann sums will be identical. Therefore the right and left sums, and their average are all equal.
Second, the area obtained from the trapezoid rule is identical to the average of left and right Riemann sums, so it's not surprising to find this parallel in our results.
Trapezoids vs. rectangles
The area under a curve calculated using the trapezoid rule is the same as the average value of the right and left Riemann sums. The trapezoid rule is a bit more compact and easier to program, so it is generally used.
Error analysis
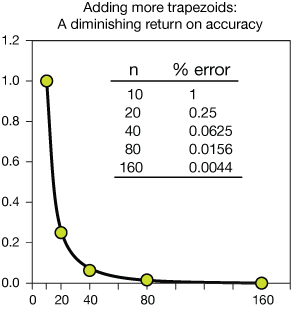
Here is a plot of the errors in several trapezoid-rule integrations of our example function above (error as a percent of the known value of 32/3). Integrations using 10, 20, 40, 80 and 160 trapezoids were performed using a spreadsheet program.
Notice that while the error becomes smaller as the number of trapezoids increases, there is a diminishing return. The difference in improvement in the percent error decreases from one trial to another. Adding more iterations has makes less of a difference as we go on.
Nevertheless, modern computers are blindingly fast at doing integrations using even 1000 trapezoids, so adequate accuracy can usually be obtained.
3. Monte Carlo integration
The city of Monte Carlo in Monaco, famous in part for its central gambling casino, was founded on the laws of probability, thus the name for this probability-based integration technique.
Some integrals are not amenable to Riemann-type integration, including trapezoidal integration, so we need another way. Monte Carlo integration is one such way.
It works like this: The area to be integrated is surrounded by a bounding box, leaving about the same area above the curve as below. Because the bounding box is a rectangle, its area is known. The yellow bounding box shown here has area $(b-a) \times (d-c)$.
Pairs of random numbers, one between $a$ and $b$, the other between $c$ and $d$, are generated using a high-quality random number generator (it's not as easy as you might think to generate truly random numbers).

Think of the resulting ordered pairs (x, y) as "darts" that are thrown randomly at the bounding box. Now some will strike below the curve and some above it. It's relatively easy to ask which are below: We just compare the random y-value of the point to the calculated y-value by plugging the random x into our function.
Now on average the probability of one of our "darts" hitting below the function is proportional to the ratio of the area under the curve to the area of the bounding box.
We estimate the area under the curve by generating thousands or millions of random points, counting the ones below the curve, and multiplying the ratio of the "hits" to the total number "thrown."
Using a 4 unit × 4 unit bounding box, three Monte Carlo integration attempts of the same example function we've used above, with n = 100, 1000 and 100,000 points yielded:

We could easily generate several million points on a computer to improve the quality of our estimate, but it's important to notice that there is a diminishing return with the Monte Carlo method, too. In fact, we'd expect that, on average, to get a one-decimal point increase in precision, we'd have to increase the number of randomly generated points tested by a factor of 100.
Implementation – some Python code
Here is a short bit of Python code that performs a Monte Carlo integration of the function $f(x)=x^4-5x^3-9x^2+45x$. This is a function for which we can obviously find the analytical integral — just a well-behaved polynomial function — but that allows us to examine the accuracy of the approximation. If you run it, you'll find that it's pretty good with a million "shots" or so.


![]()
xaktly.com by Dr. Jeff Cruzan is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License. © 2012-2025, Jeff Cruzan. All text and images on this website not specifically attributed to another source were created by me and I reserve all rights as to their use. Any opinions expressed on this website are entirely mine, and do not necessarily reflect the views of any of my employers. Please feel free to send any questions or comments to jeff.cruzan@verizon.net.