This section derives some of the properties of the uniform probability distribution function using calculus. If you can't follow that, just take the results, which are summarized in a box.
A probability density function (PDF) is a function that represents the likelihood of a probability "experiment" yielding a particular result. PDFs model continuous random variables, rather than discrete variables, though they can be applied to the analysis of discrete probabilities.
The PDF gives the probability that the value of a continuous random variable will fall within some range of that variable. It can't predict absolute likelihood because that isn't well-defined for a continuous random variable. "Continuous" means having an infinite range of values, therefore the probability of any one specific outcome among them is zero.
One of the most recognizable PDFs is the Normal or Gaussian distribution function, the "bell curve." It looks like this:

The Gaussian curve shows that the most-likely value is the mean, $\bar{x}$. We also define two points, $\bar{x} ± \sigma$, where σ is the standard deviation and $\sigma^2$ is called the "variance."
As an example of how such a distribution is used, Let's take a look at the distribution of heights of adult women living in the U.S. in 2016. The horizontal axis is height, from short on the left to tall on the right. The curve is proportional to the number of women with a given height. The average height, $\bar{x}$, was 65.5 inches.

The probability of a height falling within some range of heights is given by the area under the curve between those two heights. For this particular distribution, there is a specific range, $\bar{x} ± \sigma$ , which encloses 68% of the total probability. It shows that 68% of all U.S. women in 2016 had heights between 65.5 - 2.5 = 63 inches and 65.5 + 2.5 = 68 inches. In obtaining a curve like this, we tweak a small set of parameters to fit a Gaussian curve to the data.
In this section we'll take a look at uniform probability distrbutions, their uses and their properties. Some calculus is used to derive those features, but you can skip that and just rely on the results, summarized in a box below if you need to.
A parameter is an adjustable constant in the definition of a function that is different from the independent variable(s). Parameters are not independent variables. For example, in the quadratic function
f(x) = Ax2 + Bx + C
A, B and C are parameters which change the shape of the graph of the function. x is the independent variable. A, B and C are fixed for any particular version of f(x), but x can range from -&inf; to +&inf;
Discrete means individually separate and distinct. In mathematics, a discrete varable might only take on integer values, or values from a set {a, b, c, ... d}. In quantum mechanics, things the size of atoms and molecules can have only discrete energies, E1 or E2, but nothing in between, for example.
Use a uniform distribution when all outcomes of a probability experiment are equally possible at any time. One example is rolling a single die, for which 1, 2, 3, 4, 5, 6 have equal probabilities.
The uniform probability distribution is one in which the probability of any outcome of a probability "experiment" is the same. A good example is the rolling of a single fair die (fair means equal chance of rolling 1, 2, 3, 4, 5 or 6).
The probability of rolling a 1 is the same as that for rolling a 2 or 3, 4, 5 or 6. for each there is a 1 in 6, or ⅙ chance. We can sketch a graph of these discrete outcomes like this:
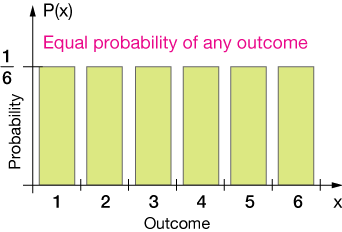
Now any probability distribution must also capture the idea of an assured outcome, that is, that when the experiment (tossing the die) is performed, some outcome is assured. The die will come up with a result.
The total probability, therefore, must sum to 1. In this case, we have six possible outcomes, each with a ⅙ probability, so the total area of our rectangular probability distribution graph (below) is 1. We would refer to this as a normalized distribution.

Coin tossing is another example of a probability experiment with a uniform distribution of outcomes. There is a ½ probability of tossing heads and a ½ probability of tossing tails, the only two possible outcomes (we can approximate the probability of a coin landing on its edge to zero). The two probabilities sum to 1.
We might also have a uniform distribution of continuous outcomes, where our probability experiment could give any result between x = a and x = b, with equal likelihood, as in the graph below.

This is the most general representation of the uniform distribution.
Now let's derive formulas for the average and variance $(\sigma^2)$ of this distribution. The average of a distribution over a range [a, b] is obtained by doing a little calculus:
$$ \begin{align} \bar{x} &= \frac{1}{b - a} \int_a^b x \, dx \\ \\ &= \frac{1}{b - a} \frac{x^2}{2} \bigg|_a^b \\ \\ &= \frac{1}{2(b - a)} (b^2 - a^2) \\ \\ &= \frac{1}{2(b - a)} (b - a)(b + a) = \bf \frac{b + a}{2} \end{align}$$
That's just what we'd expect: add the high and the low and divide by two.
The variance of a discrete distribution is
$$\sigma^2 = \frac{1}{N} \sum_{i = 1}^N (x_i - \bar{x})^2$$
For our continuous distribution, we integrate that definition on the interval $[a, b]$, where $\bar{x} = \frac{a + b}{2}$:
$$ \begin{align} \sigma^2 &= \frac{1}{b - a} \int_a^b (x - \bar{x})^2 \, dx \\ \\ &= \frac{1}{b - a} \int_a^b \left[ x - \frac{a + b}{2} \right]^2 \, dx \\ \\ &= \frac{1}{b - a} \int_a^b \left[ x^2 - 2x \left( \frac{a + b}{2} \right) + \frac{(a + b)^2}{4} \right] \, dx \\ \\ &= \frac{1}{b - a} \left[ \frac{x^3}{3} - x^2 \left( \frac{a + b}{2} \right) + \frac{(a + b)^2 x}{4} \right]_a^b \\ \\ &= \frac{1}{b - a} \left[ \frac{b^3 - a^3}{3} + (a + b)\left( \frac{a^2}{2} - \frac{b^2}{2} \right) + \frac{(a + b)^2}{2} (b - a) \right] \\ \\ &= \frac{b^2 + ab + a^2}{3} - \frac{a^2 + 2ab + b^2}{2} + \frac{a^2 + 2ab + b^2}{4} \\ \\ &= 4b^2 + 4ab + 4a^2 - 6a^2 - 12ab - 6b^2 + 3a^2 + 6ab + 3b^2 \\ \\ &= \frac{b^2 - 2ab + a^2}{12} = \bf \frac{(b - a)^2}{12} \end{align}$$
The uniform probability distribution function is
$$P(x) = \frac{1}{b - a} \; \text{ for } \; x \in [a, b]$$
The mean of a uniform PDF over the domain [a, b] is
$$\bf \bar{x} = \frac{b + a}{2}$$
The variance of a uniform PDF over the domain [a, b] is
$$\bf \sigma^2 = \frac{(b - a)^2}{12}$$
Let's say we have a shoe store that sells pairs of shoes with a uniform probability of a sale throughout a seven-day week. That is, it's equally probable that a pair of shoes is sold on Monday as on Tuesday. The minimum number of pairs sold per week is 50, and the max is 250. Calculuate the probability of selling between 100 and 150 pairs of shoes. Calculate the mean and standard deviation, $\sigma = \sqrt{\sigma^2}$ of the distribution.
$$P_{100-150} = (150 - 50) \cdot \frac{1}{250 - 50} = \frac{100}{200} = \frac{1}{2}$$
The mean of the distribution is
$$\bar{x} = \frac{a + b}{2} = \frac{50 + 250}{2} = 150 \; \text{pairs}$$
Finally the variance is
$$ \begin{align} \sigma^2 &= \frac{(b - a)^2}{12} \\ \\ &= \frac{(250 - 50)^2}{12} = 3,333 \\ \\ &\text{so }\; \sigma = \sqrt{3333} = 58. \end{align}$$
The mean is $150 ± 58 \text{ pairs}$
Most computer programming languages and numerical programs (like spreadsheets) are capable of generating pseudo-random numbers, numbers that span the range [0, 1]. Let's calculate the mean of that distribution, its variance and standard deviation, and the probability of generating a random number between, say, 0.8 and 0.9.
$$\bar{x} = \frac{a + b}{2} = \frac{0.0 + 1.0}{2} = 0.5$$
The standard deviation is
$$ \begin{align} \sigma^2 &= \frac{(b - a)^2}{12} \\ \\ &= \frac{(1.0 - 0.0)^2}{12} = 0.08333 \\ \\ &\text{so }\; \sigma = \sqrt{0.08333} = 0.289 \end{align}$$
Finally, the probability of generating a random number between 0.8 and 0.9 is
$$P_{0.8-0.9} = (0.9 - 0.8) \cdot \frac{1}{1.0 - 0.0} = \frac{0.1}{1} = 0.1$$
I wrote a short Python program (below) to generate some random numbers between 0 and 1.0, and calculate the mean and standard deviation. Here are the results of five runs of the program testing 1000 random numbers (top block) and 100,000 numbers.
Notice that the mean and standard deviations match our predictions, and that they're closer for the 100,000-number group of experiments, an illustration of the law of large numbers.

Here is a short Python program that you could copy and run to calculate the mean and standard deviation of a set of random numbers generated between 0 and 1.0. Remember that anything behind a # is just a comment to help you better understand what the code is doing.


![]()
xaktly.com by Dr. Jeff Cruzan is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License. © 2016, Jeff Cruzan. All text and images on this website not specifically attributed to another source were created by me and I reserve all rights as to their use. Any opinions expressed on this website are entirely mine, and do not necessarily reflect the views of any of my employers. Please feel free to send any questions or comments to jeff.cruzan@verizon.net.
