What claims are statistically significant?
An event or an outcome of some experiment is statisically significant if it is unlikely to have occurred by random chance. Our job in this section will be to understand some common ways we distinguish claims as likely or unlikely to have occurred by random chance.
We'll do that by comparing some test statistic with the appropriate probability distribution (like the normal distribution, but we'll also refer to the t-distribution) and asking how likely it is that such a value would arise.
Something is statistically significant if it is unlikely to have occured by random chance.
Here's the basic idea in a picture:

The mark labeled "statistically significant" signifies the point beyond which we might believe a result is unlikely to have occurred by random chance (blue region). That is, a test statistic value at or beyond this point would be so improbable that it must be meaningful, or else we've just observed a very rare event. In this case, because the probability distribution is symmetric, we'd probably put one on the left side, too: any value beyond the mark on either end would be considered to be statistically significant.
Just where we put that mark is a matter of judgment, and of the context of the problem at hand. It's one of the topics of this page.
On this page we'll introduce the concept of significance testing by trying a couple of things that work mostly (and are certainly good for figuring out the concept), but refining those toward the introduction of the P value for evaluating a claim. Along the way we'll have to define some vocabulary that will likely be uncomfortable at first, but it's the language of the field so we need to learn it.
Let's go.
How to write "P value "
Various academic organizations and journals write the term P value in different ways, such as p value, P-value, p-value ... I'll stick with the Nature Magazine style and use a capital P with no hyphen: P value
The essence of statistics
In this section we really get to the heart of the study of statistics. Very often you'll be presented with conclusions that may or may not have been based upon good data. Your job, at least as a citizen, will be to distinguish whether that result is statistically significant — whether it has real meaning — or whether it might just as well have occured by random chance.
Hypotheses
In significance testing, we are always testing a hypothesis in a binary (true | false) fashion — is our hypothesis true or not, and if not, what do we conclude must then be true?
We always test a null hypothesis, $H_o,$ to see whether it is true in the given situation. If it is not, we reject it and default to an alternative hypothesis, $H_a.$ These can be confusing terms, and like a lot of the language of math and science, there's not much we can do about it. The word "null," for example, doesn't have the same meaning (like "having no legal or binding force" or "void" or "the empty set or zero") that it usually does in more common use. Instead, the null hypothesis might better be interpreted as the status quo — that is, what we expect the answer to be given our knowledge of the population with which we're working.
Here are some examples of null and alternative hypotheses:
| $H_o$ (null hypothesis) | $H_a$ (alternative) |
|---|---|
| The population proportion is 73% | The population proportion is less than 73% |
| $H_o: \, \mu = 2.1$ | $H_a: \, \mu \ne 2.1$ |
| The mean weight of babies born in Utah is 7.45 lbs. | The mean weight is greater than 7.45 lbs. |
The alternative hypothesis, $H_a$, is what we must default to if the null hypothesis is rejected. We can perform
- One-tailed tests
- Two-tailed tests
A one-tailed test is performed when the alternative hypothesis states that the value of a parameter is either greater than or less than the value indicated by the null hypothesis. For example, the hypotheses:
- $H_o: \, \mu = 2.35 \phantom{000} H_a: \, \mu \gt 2.35$
- $H_o: \, \mu = 5.98 \phantom{000} H_a: \, \mu \lt 5.98$
are both one-tailed problems because we're only asking whether our test statistic is greater than or less than the null-hypothesis value, to an extent that convices us that the difference couldn't have happened by random chance.
A two-tailed test is made when we have hypotheses that look like
$$H_o: \, \mu = 2.35 \phantom{000} H_a: \, \mu \ne 2.35$$
In this case, we'd be surprised by a value some specified distance to the right of the mean $(\mu)$, but equally suprised if it were the same distance from the mean toward the left side of the distribution — toward the other tail. "Surprised" here means that there would be enough evidence to reject our null hypothesis.
In most significance testing, we'll assume a confidence level, $\alpha$, but in cases where $\alpha$ isn't specified, we'll often assume some reasonable value.
The null hypothesis usually isn't an inequality like $H_o: \, \mu \lt 2.45$.
Null hypothesis $(H_o)$: the status quo or the expected outcome
$H_o$ is often pronounced "H sub naught" or just "H naught"
Alternative hypothesis $(H_a)$: what we accept to be true after understanding that we have enough evidence to reject the null hypothesis
The rejection-region approach
Read this section to understand the general idea and see some examples. We'll move on from this toward a more sophisticated way of looking at significance down below, but it's good to begin here.
For now, a good way to look at hypothesis testing is the rejection region. To evaluate a claim against some null hypothesis, $H_o$, we need to first set some level beyond which we'll say "That couldn't have happened purely by random chance." We'll specify a number, $\alpha$, which we'll call the significance level. The corresponding complement, $1 - \alpha$, leads to the confidence interval. There are a few ways this could look. The first is a two-tailed test.
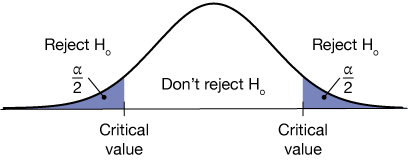
In the graph above, we are testing a hypothesis, $H_o: \mu = \mu_o$, against an alternative hypothesis $H_a: \mu \ne \mu_o$. That is, our null hypothesis is that the population mean is equal to some specified value, $\mu_o$, and our alterantive is that it is not. Notice that in this analysis, the statistic we're testing could be greater than the expected mean or smaller. We call this a two-tailed hypothesis, and we break the confidence level, $\alpha$ into two parts of size $\alpha/2$ on the left and right sides. These are labeled with a number called the critical value.
A value of our test statistic that falls inside either of those (blue) rejection regions causes us to reject the null hypothesis. Otherwise, we do not reject it.
We could also have a null hypothesis $H_o: \mu = \mu_o$, with an alternative hypothesis that $H_a: \mu \gt \mu_o$. This leads to the one-tailed test in the figure below. We'll see some details of how these are constructed later in this section, but for now, if the value of the test statistic falls to the right of some critical value, we reject the null hypothesis and conclude that indeed, $\mu \gt \mu_o$.
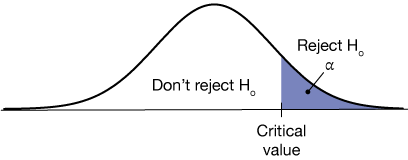
Here's that same situation for the alternative hypothesis $H_a: \mu \lt \mu_o$. The null hypothesis is rejected if the test statistic value is less than the critical value.
Now let's get a little more specific with these examples. Let's assume an alpha level of $\alpha = 0.05$, which would go with a confidence interval of 95%. If our null hypothesis is $H_o: \mu = \mu_o$ and our alternative is $H_a: \mu \ne \mu_o$, then we break the 5% of the area under the normal curve into two equal pieces, right and left, as shown.
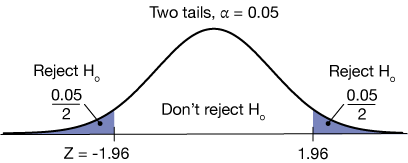
Using a standard normal table or the invNorm( ) function on a TI-84 calculator,
invNorm(0.025, 0, 1) = -1.96
we can determine the Z-score that goes with an area of 0.025 (2.5%) on the left and right. Those values are (because of the symmetry of the normal distribution) ±1.96, as shown. Now we reject the null hypothesis if the Z-score of our test statistic is less than -1.96 or greater than 1.96.
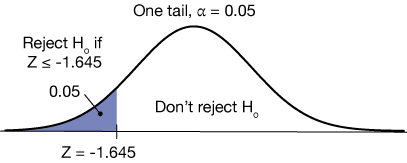
If the null hypothesis is $H_o: \mu = \mu_o$ and the alternative hypothesis is $H_a: \mu \gt \mu_o$, with the same level of confidence, then we place the entire 5% of the area under the SND on the right side of the distribution as shown here:

Now the Z-score that goes with an area on the right of 0.05 can be calculated using a TI-84 calculator like this:
invNorm(0.05, 0, 1) = -1.645
We take the positive value. The TI-84 performs the calculation from the left side of the distribution as a default, but we use the symmetry to get the value on the right. So any Z-score of our test statistic greater than or equal to 1.645 is a rejection of our null hypothesis.
Finally, for the same null hypothesis, we could have an alternative $H_a: \mu \lt \mu_o$, leading to the one-tailed test below. In this test, if the Z-score of the test statistic is less than -1.645, the null hypothesis is rejected and we conclude that the mean $\mu$ must be less than the value $\mu_o$.
$\alpha$ and 1 & 2-tailed tests
For a given significance level, $\alpha$, for a one-tailed test (either side), we take the whole value of $\alpha$, the area under the standard normal curve, to be on one side.
For a two-tailed test, the area $\alpha$ is split evenly between the tails, $\alpha/2$ on either side.
Example 1
Let the null hypothesis be $H_o: \, \mu = \mu_o$ and the alternative be $H_a: \, \mu \gt \mu_o$. Using a significance level of 10% $(\alpha = 0.10)$, determine whether a test statistic that yields a Z score of 4.2 is cause for rejection of the null hypothesis.

The Z-score for this situation is calculated on a TI-84 calculator like this:
invNorm(0.10, 0, 1) = 1.281
(Note, if you enter this into your TI-84, it will likely give you the negative value. That's OK; it's just an artifact of the way the algorithm works. It adds up – integrates – area under the standard normal curve from left to right.)
Now a Z-score of 4.2 is well within our rejection region, $4.2 \gt 1.281$, so we reject the null hypothesis and conclude that the mean, $\mu$ must be greater than $\mu_o$. In other words, a test statistic with a Z-score of 4.2 is a statistically-significant result.
Pro tip
At the end of a significance test we say that we "reject the null hypothesis" or we "fail to reject the null hypothesis."
Example 2
Let the null hypothesis for some problem be $H_o: \, \mu = \mu_o$ and the alternative be $H_a: \, \mu \ne \mu_o$. Using a significance level of 5% $(\alpha = 0.05)$, determine whether a test statistic that yields a Z score of -8.0 is cause for rejection of the null hypothesis.

The Z-score for this situation is calculated on a TI-84 calculator like this:
invNorm(0.025, 0, 1) = 1.96
So our two rejection-region limits (just using the symmetry of the normal distribution) are $±1.96$.
Now a Z-score of -8.0 is well inside of the left-side rejection region, therefore we reject our null hypothesis and conclude that the mean $\mu$ is not equal to $\mu_o$.
We're concluding that the datum that led to a Z-score of -8.0 is so unlikely to have occurred that it is unlikely to have been obtained by random chance. That points to an error in the null hypothesis.
The problem with the rejection-region approach
The rejection region approach is pretty coarse – no subtlety. Consider this example as an illustration. Let's do a one-taied evaluation of a null hypothesis, $H_o: \, \mu = 2.0$, where we'll assume that the standard deviation of the population is known to be $\sigma = 0.5$. Our alternative hypothesis will be $H_a: \, \mu \lt 2.0$. Let's evaluate a value of $\bar x = 1.85$ from a sample of 32 observations, using a confidence level of $\alpha = 0.05$.
The distribution looks like this:

Our Z-score is
$$ \begin{align} Z &= \frac{\bar x - \mu}{\frac{\sigma}{\sqrt{n}}} \\[5pt] &= \frac{1.86 - 2.0}{\frac{0.50}{\sqrt{36}}} \\[5pt] &= -1.68 \end{align}$$
Now we can conclude that this mean is cause to reject the null hypothesis, but just barely $(-1.68 \lt -1.645)$, and that's a problem. We have no way to tell the difference between an observation that clearly rejects a null hypothesis and one that barely does. That's where the P-value will come in, so let's get started on that.
P values
We saw above that we need a way to measure the likelihood of some outcome (the value of a test statistic) to see if it's statistically significant. Remember, that's how we judge whether to reject a null hypothesis or keep it. We turn to the P value (capital P, no hyphen).
The P value is the probability of getting an observed value of a test statistic or a value with even greater evidence against the null hypothesis.
The P value is the probability of observing a value of a test statistic at least as extreme as the value already observed.
Sufficient evidence
Here's the idea. Take a normal distribution and define our "alpha level" that represents the division between what we believe could happen by random chance and what probably doesn't. In this representation of a two-tailed test, we shade in the areas in the intervals $(-\infty, \; -\alpha/2)$, and $[\alpha/2, \; -\infty)$ (gray) to show those regions of the distributions. In so doing, we're stating that outcomes that fall within those regions on the x-axis are improbable, and therefore statistically significant.

The purple area is our P value. It is calculated by finding the Z-score (if we're working with normally-distributed data) of our test statistic and calculating the area under the distribution beyond it (purple area).
In the illustration, the test statistic falls well within the gray area — its area is smaller, so we conclude that the value we got — or anything more extreme than it — is statistically significant, and we have evidence to reject the null hypothesis.
Here is the same scenario, but with the P value area on the other side of the distribution, the area calculate between -∞ and a critical Z-score (or another critical value as we'll see soon).

Insufficient evidence
Now let's look at a significance test using a P value that would fail to reject $H_o$. In this case, the P value (the area of the blue region), representing the probability of obtaining the test statistic or anything with even more evidence against $H_o$, covers some of the area under the normal curve that is in the region we'd say could represent occurrence by random chance, so we lack the evidence needed to reject the null hypothesis.

P value
The P value is the probability, computed by assuming that $H_o$ is true, that the test statistic (such as $\hat p$ or $\bar x$) would take a value as extreme as or more extreme than the one actually observed, inthe direction specified by $H_a$.
Example 3
A national high school exam is scaled so that the mean of the normally-distributed scores is 500±100 (100 = one standard deviation). In a class of 30 students, one teacher notes a mean score of 473. The teacher wonders if this class is truly below average, so she calculates a one-tailed hypothesis test with $H_o: \; \bar x = 500,$ $H_a: \; \bar x \lt 500$, and $\alpha = 0.05$.
$$Z = \frac{\bar x - \mu}{\frac{\sigma}{\sqrt{n}}} = \frac{473 - 500}{\frac{\color {red} {100}}{\sqrt{30}}} = -1.4788$$
The Z-score for our $\alpha = 5%$ cutoff on the left is $Z_{\alpha} = -1.6449.$
The graph shows that our P-value, the area enclosed by the SND up to the Z-score of our test statistic, Z = -1.4788, is P = 0.0696, which is above our significance level of 0.5. So this situation is not less-likely than our significance level, and we conclude that a 30-class member average score of 473 could indeed have occured by random chance; the teacher's students are not necessarily a low-performing class.
The Z = -1.6449 is just the Z-score that encloses 5% of the probability on the left side of the SND.
Conclusion:The null hypothesis holds, and we conclude that a sample mean of 473 is acceptable (could have occurred by random chance).

Example 4
In a factory, one component will fit into its place only if its length is between 6.2 and 6.3 cm. The lengths of this component vary slightly, with $\sigma = 0.021 cm.$ The distribution of lengths is approximately normal. The average length of the component, $\mu,$ can be set by software on the machine. When the machine is set to a length of 6.25 cm and the operator tests 100 parts, she finds an average length of $\bar x = 6.2516$ cm. Test the hypotheses $H_o: \; \bar x = 6.25$ and $H_a: \; \bar x \ne 6.25$ at a level of significance of $\alpha = 0.10$.

Now the Z-score for a mean length of 6.2516 cm is
$$Z = \frac{\bar x - \mu}{\frac{\sigma}{\sqrt{n}}} = \frac{6.2516 - 6.25}{\frac{0.021}{\sqrt{100}}} = 0.7619$$
The P-value, because of the symmetry of the problem, is twice the area contained between, $Z = 0.7619$ and the right extreme of the SND, which we can find using the normalcdf( ) function on a TI-84 calculator:
normalcdf(0.7619, 1E99, 0, 1) = 0.2230
Twice that value is 0.446. This is much larger than our level of significance, so this average length checks out as highly probable just due to random chance. Notice that in the figure below the purple shaded area encompasses our 10% alpha level, and goes beyond it, into the region where we've agreed results could occur by random chance.

Example 5
Let's say we know that the average weight of 3rd graders in the U.S. is 84 ± 19 lbs. (one standard deviation). If a teacher measures the weights of 25 students in a of 3rd-grade class and finds $\bar x = 96$ lbs., might we conclude that these students might not be third graders?
Now the Z-score for our observed average weight is
$$Z = \frac{\bar x - \mu}{\frac{\sigma}{\sqrt{n}}} = \frac{96 - 84}{\frac{19}{\sqrt{25}}} = 3.1579.$$
Now let's use the normalcdf function on a TI-84 calculator to find the total area (probability) bounded between Z = 3.1579 and ∞:

That is quite a small area, 0.08% of the total. Our P-value is 0.0.0016 or 16%, which falls well within our level of significance. Here it is in picture form.

We have to conclude that our null hypothesis is false, and that these are not likely to be third graders. Because we did a two-tailed test, we have a little more information: The sample mean is greater than the population parameter, so we could probably conclude that this group is older than 3rd-grade age.
Another way to interpret this result is that if the null hypothesis were true, we'd find this size of sample average far less frequently than 5% of the time.
t-test – when the population σ isn't known
When samples of a large population are taken in order to estimate a population parameter like a mean, $\mu$, we don't usually know the population standard deviation. If we did, we have to have taken a census, and that's what we're trying to avoid. How to get around this?
We do it by using the standard error of the sample, $SE$, the standard deviation of the sample, $s$, divided by the number of individuals in it, $n$.
$$SE = \frac{s}{\sqrt{n}}.$$
Then the position of our test statistic in its distribution, by analogy with the Z-score from the normal distribution, is
$$t^* = \frac{\mu - \mu_o}{\frac{s}{\sqrt{n}}}$$
Notice that we did not call this a Z-score, but labeled it $t^*$, which stands for the "critical t value." When we use the sample standard error, the distribution of outcomes no longer conforms to a normal distribution, but rather a t distribution. Now we'll explore that distribution a bit.
The t distribution
The t-distribution, sometimes called Student's t-distribution — "Student" was the name of the person who figured it out. Recall that the normal distribution is completely determined by two parameters, the mean, $\mu$, which locates the center of the distribution on a number line, and the standard deviation, $\sigma$, which determines its width. The t distribution is characterized by three parameters, a mean, the standard error and the number of degrees of freedom, in the data, which we call $df$.
The number of degrees of freedom is one less than the number of individuals in the sample: $df = n - 1$. You might recognize this notion from the definition of the sample standard deviation,
$$\sigma = \sum_{i=1}^N \frac{x_i - \bar x}{N - 1}$$
where we subtract one from the number of individuals in the sample, $N$, because we've essentially used one of them to calculate the mean of the data, $\bar x$.
The appearance of the t-distribution varies according to the number of degrees of freedom. Here are a few t distributions with a mean of zero and a standard error of 1, plotted on the same graph.

Notice that as the number of degrees of freedom increases, the t-distribution converges (gets closer to) with the normal distribution. The gray area is blown up below. Notice that the tails of the t-distribution enclose more area than the normal distribution, so any P values we derive using the t-distribution will be greater, too.

While the t-distribution approaches the normal distribution when $df$ gets large, it's not a good practice just ot use the normal distribution in those cases. Sticking to the t-distribution is the way to go.
By analogy with the normal distribution functions on the TI-84 calculator, we can use two important functions to find areas under t-distributions and to find so-called critical t-values, $t^*$, from areas. Those functions are, respectively,
tcdf(t*, 1E99, df) = area
where 1E99 is just a large number signifying an area between t* and the extreme right tail of the distribution, and
invT(area, df) = t*
T vs. Normal distribution
The T-distribution is similar to the normal distribution except that the latter is a function of the known mean $\mu$ and its standard deviation $\sigma$. The T-distribution does not assume knowledge of those parameters, and is instead a function of the number of degrees of freedom of the problem — the number of data points minus one.
For a small number of degrees of freedom, the "wings" of the T-distribution are wider than those of the Normal distribution. But as the number of degrees of freedom increases, the two distributions converge.
Move the slider under the graph to change the number of degrees of freedom between 1 and 21 to see that convergence.
Black = T-distribution
Red = Normal distribution
* Note on the simulation: Calculation of the T-distribution requires evaluation of the Gamma function, $\Gamma(X)$, for which I've used a bit of an approximation. That approximation breaks down slightly for larger degrees of freedom, and that's why the T-distribution curve (black) pops up above the Normal distribution for larger numbers of degrees of freedom; it shouldn't. My point was more to illustrate the differences in the wings, so that's fine with me.
Example 6
A 68 g Chocolate Brownie Clif Bar™ contains 10 grams of protein, as indicated on the label. Let's say that we take a sample of 30 bars and measure the protein concentration, obtaining these (made-up) results:
| 9.45 | 9.87 | 10.23 | 9.98 | 10.11 |
| 10.33 | 10.02 | 10.72 | 9.98 | 9.91 |
| 10.05 | 10.11 | 10.23 | 9.67 | 10.04 |
| 9.45 | 9.87 | 10.23 | 9.98 | 10.11 |
| 10.35 | 10.37 | 10.28 | 9.72 | 9.87 |
| 9.45 | 10.87 | 10.00 | 10.40 | 9.98 |
Let's do a t-test on this sample to evaluate whether that sample mean protein mass is reasonable with a level of significance of $\alpha = 0.05.$
The t-value for $\alpha = 0.025$ and 30 - 1 = 29 degrees of freedom is t = 2.0452, found using
invT(0.025, 29) = -2.0542
on a TI-84 calcuator. The negative sign is an artifact of the way the TI-84 calculates t-values (it works from the far-left side of the distribution toward the right until it's counted the specified area, then marks the t-value there), but they are symmetric about the mean of zero, so we'll pick the positive one. The t-value of our sample mean, $\bar x,$ is
$$t = \frac{\bar x - \mu}{\frac{s}{\sqrt{n}}},$$
where $s$ is the sample mean instead of the population mean, which is unknown in this case – and in most cases. Remember also that the term $s / \sqrt{n}$ is called the standard error. The t-value is
$$t = \frac{10.0543 - 10.0}{\frac{0.3295}{\sqrt{30}}} = 0.9026$$
The P-value is just the area under the t-distribution to the right of t = 0.9026 plus that to the left of t = -0.9026. I'ts illustrated by the pink area in the distribution below. The area was calcuated by using the tcdf() function on a TI-84 calculator:
tcdf(0.9026, 1E99, 29) = 0.1871

Doubling that calculated area gives a total probability outside of our observed average of about 36%, so we'd conclude that an average of 10.0543 g of protein would not be unlikely at all; this data fits the company's assertion.
Solving significance-testing problems

This flowchart might help you to perform the various kinds of significance tests. It begins with some population, for which we know or have some reliable estimate of a parameter, either a mean (μ) or a proportion (p).
For sample means problems, either the standard deviation (σ) of that parameter is known or it is not. "Not" is usually the case.
If σ is known, then we use a simple Z-test as in the examples above. That is, we use Z-scores and the standard normal distribution to find probabilities. For these we can use tables of the area under a SND, or we can use functions like
normalcdf() & invnorm()on a TI-84 calculator.
If σ is not known, we use the t-distribution to calculate t instead of Z, then use similar tables or calculator functions to calculate the associated probabilities.
For proportions problems, the approach is the same either way.
Practice problems
-
Let's say that it has been determined by health authorities that mercury (Hg) levels higher than two parts per billion (ppb) are unsafe for human consumption in drinking water. You are responsible for determining whether drinking water is safe based on taking 100 (total) water samples from two different parts of the city. Let's say that the average of those 100 measurements was [Hg] = 2.20 ± 0.52 ppb. Use the appropriate significance test with an α level of 0.05 to determine whether the 2.20 ppb concentration is a statistically-significant result. Should authorities take measures to reduce the mercury content of the water?
Solution
This is a means problem in which we don't know the standard deviation of the population, only of the sample of 100. Thus, this is a t-distribution problem.
First, our null and alternative hypotheses are
$$ \begin{align} H_o: \, \mu &= 2.00 \\[5pt] H_a: \, \mu &\gt 2.00 \end{align}$$
Note that we're only really interested in whether the mercury level is higher than allowed, so this is a one-tailed problem.
Now let's calculate the critical t value, $t^*$, given a significance level of α = 0.05 and 99 degrees of freedom:
invT(0.05, 99) = 1.60
Now the t value for our sample is
$$ \begin{align} t &= \frac{\bar x - \mu}{\frac{s}{\sqrt{n}}} \\[5pt] &= \frac{2.20 - 2.00}{\frac{0.52}{\sqrt{100}}} \\[5pt] &= \frac{0.20}{0.052} = 3.84 \end{align}$$
Now $3.84 \gt 1.6$, so this result is statistically significant, and and we should conclude that the mercury level is high, demanding action to reduce it.
-
A political polling firm wishes to determine whether a majority of Oregon voters would vote for a certain state constitutional amendment. The firm has the opinions of 1000 randomly-sampled voters. What hypotheses and significance test might you set up to determine whether the amendment is likely to pass?
Solution
This is a proportions problem. What we care about is whether the proportion of voters who support the amendment is greater than 0.5 or 50%.
Our null and alternative hypotheses would then be
$$ \begin{align} H_o: \, P &= 0.50 \\[5pt] H_a: \, P &\gt 0.50 \end{align}$$
Our null hypothesis is that the amendment will (narrowly) not pass, and the alternative is that it will. We might also write the null hypothesis as $H_o: \, P \le 0.50$.
-
A cookie baker has determined that it makes the most profit per chocolate-chip cookie if each has 15 chocolate chips. Any more chips makes the cookie too expensive, and fewer chips leads to fewere sales. In a test of 500 cookies, the baker found an average of 15.5 ± 1.1 chips (one standard deviation). Should the baker adjust the number of chips in its cookies? Use an α level of 0.05 for this test.
Solution
This is a means problem in which we don't know the standard deviation of the population, only of the sample of 500. Thus, this is a t-distribution problem.
First, our null and alternative hypotheses are
$$ \begin{align} H_o: \, \mu &= 15.0 \\[5pt] H_a: \, \mu &\ne 15.0 \end{align}$$
Here we're interested in whether the number of chips deviates from the optimum number of 15, so this will be a two-tailed analysis.
Now let's calculate the critical t value, $t^*$, given a significance level of α = 0.05 and 499 degrees of freedom:
invT(0.025, 499) = 1.9647
Now the t value for our sample is
$$ \begin{align} t &= \frac{\bar x - \mu}{\frac{s}{\sqrt{n}}} \\[5pt] &= \frac{15.0 - 15.5}{\frac{1.1}{\sqrt{500}}} \\[5pt] &= \frac{0.20}{0.052} = 10.16 \end{align}$$
Now a t-value of 10.16 yields a very small area under the t-distribution, much smaller than the area marked off by the critical t-value, so this P value will be very small, small enough to reject the null hypothesis, and suggest to the cookie baker that they should dial back the number of chips per cookie.
-
Natural cork in wine bottles can deteriorate over time, allowing oxygen into the bottle and degradation of the wine. The article "Effects of bottle closure type on ponsumer perceptions of wine quality," Amer. J. Enology & Viticulture, 182-191 (2007), reported that, in a tasting of several commercially-made Pinot Noir wines, 16 of 91 bottles were considered spoiled to some extent due to cork-related effects. Does this data present strong evidence for concluding that more than 15% of all such bottles are contaminated in such a way? Use a significance level of α = 0.01 to perform this test.
Solution
This is a proportions problem, with $\hat p = \frac{16}{91} = 0.1758.$ Our null hypothesis is that the number of contaminated bottles is less than 15%, and our alternative is that the actual number is greater than that:
$$ \begin{align} H_o: \, \mu &= 0.15 \\[5pt] H_a: \, \mu &\ge 0.15 \end{align}$$
The Z score for an alpha level of 0.01 is 2.3263, which we obtain from
invNorm(0.01, 0, 1) = -2.3263
using a TI-84 calculator.
Now the Z-score for this situation is
$$ \begin{align} Z &= \frac{\hat p - p}{\sqrt{\frac{p(1-p)}{n}}} \\[5pt] &= \frac{0.1758 - 0.15}{\sqrt{\frac{0.15(1-0.15)}{91}}} \\[5pt] &= 0.689 \end{align}$$
This Z-score yields an area under the normal distribution of
normalcdf(0.689, 1E99, 0, 1) = 0.2454
which is larger than our α level, so we fail to reject the null hypothesis.
artifact
In math and science, an artifact is something that happens as the result of applying a certain method to a problem. It is usually expected and easily corrected for if needed. For example, in some X-ray scans, parts of the image might look like a tumor, but qualified interpreters might recognize the object as having resulted from some well-known phenomenon having to do with the imaging technique.
hypothesis/hypotheses
A hypothesis is a proposed explanation of some phenomenon or occurrence based on limited evidence, and usually proposes a path for further research.
The plural of hypothesis is hypotheses.
status quo
status quo is a latin phrase menaning the existing state of affairs, or the way things are now or the way things are expected to be.
Example: "Instead of revising the taxation system, the congress opted for the status quo."
binary
In science (and other aspects of life), binary can mean composed of two parts, such as a binary star system, which is composed of two stars that orbit one-another.
Binary in mathematics often indicates a dichotomy — either this or that, such as the binaries on|off, 1|0 or true|false.
naught
Naught (pronounced like "not") means nothingness. One use is in phrases like, "All of his grand plans came to naught."
In mathematics, naught just refers to the digit zero.

![]()
xaktly.com by Dr. Jeff Cruzan is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License. © 2012-2025, Jeff Cruzan. All text and images on this website not specifically attributed to another source were created by me and I reserve all rights as to their use. Any opinions expressed on this website are entirely mine, and do not necessarily reflect the views of any of my employers. Please feel free to send any questions or comments to jeff.cruzan@verizon.net.